
to make future
together.
My Work and Thoughts.
Guest Blog by Jeffrey L Mckinstry.
To seek feedback from fellow scientists, my colleagues and I are very excited to share a preprint with the community.
Title: Discovering Low-Precision Networks Close to Full-Precision Networks for Efficient Embedded Inference
Authors: Jeffrey L. McKinstry, Steven K. Esser, Rathinakumar Appuswamy, Deepika Bablani, John V. Arthur, Izzet B. Yildiz, Dharmendra S. Modha
Abstract: To realize the promise of ubiquitous embedded deep network inference, it is essential to seek limits of energy and area efficiency. To this end, low-precision networks offer tremendous promise because both energy and area scale down quadratically with the reduction in precision. Here, for the first time, we demonstrate ResNet-18, ResNet-34, ResNet-50, ResNet-152, Inception-v3, densenet-161, and VGG-16bn networks on the ImageNet classification benchmark that, at 8-bit precision exceed the accuracy of the full-precision baseline networks after one epoch of finetuning, thereby leveraging the availability of pretrained models. We also demonstrate for the first time ResNet-18, ResNet-34, and ResNet-50 4-bit models that match the accuracy of the full-precision baseline networks. Surprisingly, the weights of the low-precision networks are very close (in cosine similarity) to the weights of the corresponding baseline networks, making training from scratch unnecessary.
The number of iterations required by stochastic gradient descent to achieve a given training error is related to the square of (a) the distance of the initial solution from the final plus (b) the maximum variance of the gradient estimates. By drawing inspiration from this observation, we (a) reduce solution distance by starting with pretrained fp32 precision baseline networks and fine-tuning, and (b) combat noise introduced by quantizing weights and activations during training, by using larger batches along with matched learning rate annealing. Together, these two techniques offer a promising heuristic to discover low-precision networks, if they exist, close to fp32 precision baseline networks.
Link: https://arxiv.org/abs/1809.04191
Motivation
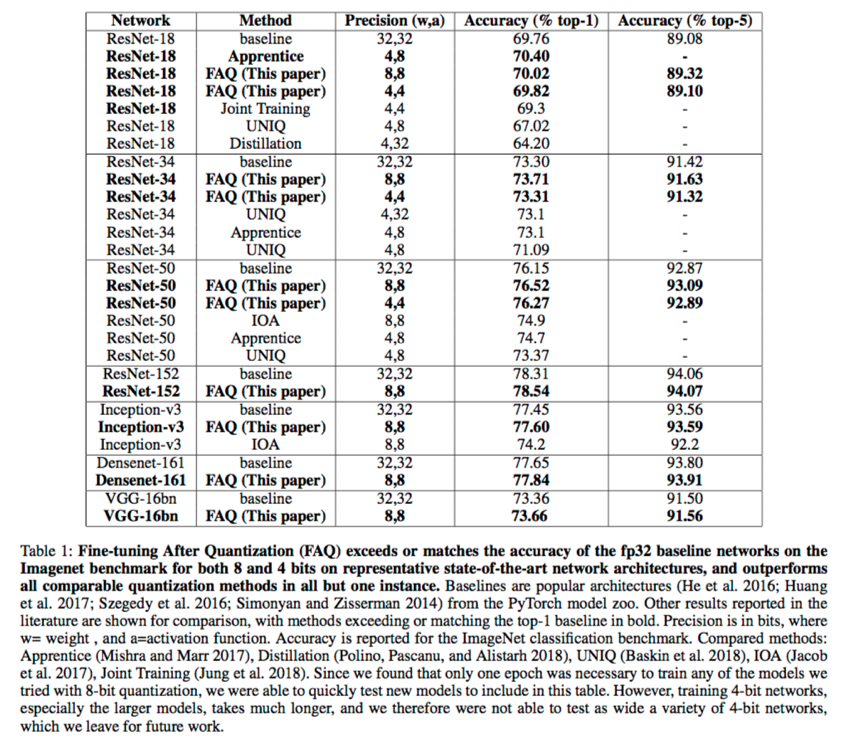
To harness the power of deep convolutional networks in embedded and large-scale application domains, for example in self-driving cars, requires low-cost, energy-efficient hardware implementation. One way to reduce energy and hardware cost is to reduce the memory usage of the network by replacing 32-bit floating point weights and activations with lower-precision, such as 8- or even 4-bits. If such low-precision networks were just as accurate as the 32-bit floating point (fp32) version, the energy and system cost savings would come for free. Unfortunately, the accuracies are lower for the 8-bit networks than for the corresponding full-precision net (see Table 1, from https://arxiv.org/abs/1809.04191). The situation is even worse for 4-bit precision. For the ImageNet classification benchmark, no method has been able to match the accuracy of the corresponding full-precision network when quantizing both the weights and activations at the 4-bit level. Closing this performance gap has been an important open problem until now.
Contributions
Guided by theoretical convergence bounds for stochastic gradient descent (SGD), we propose fine-tuning, training pretrained high-precision networks for low-precision inference, by combating noise during the training process as a method for discovering both 4-bit and 8-bit integer networks. We evaluate the proposed solution on the ImageNet benchmark on a representative set of state-of-the-art networks at 8-bit and 4-bit quantization levels (Table 1). Contributions include the following.
Fine-tuning after Quantization (FAQ)
Our goal has been to quantize existing networks to 8 and 4 bits for both weights and activations while achieving accuracies that match or exceed the corresponding full-precision networks. For precision below 8 bits, the typical method that we used in our prior work (Esser et al, 2016) is to train the model using SGD while rounding the weights and neuron responses.
In our experience, there are at least two problems faced when training low-precision networks: learning in the face of low-precision weights and activations, and capacity limits in the face of these constraints. It has been known for some time that 8-bit networks are able to come close to the same accuracy as the corresponding 32-bit network, even without retraining, indicating that 8-bit networks have approximately the same capacity as the fp32 networks. Very recently it was shown, for ResNet-18 and 50, that networks with 4-bit weights and activations could come within 1% of the accuracy of the fp32 networks when training from scratch, suggesting that 4-bit networks may also have the same capacity as the corresponding fp32 networks. We therefore looked for a way to train low-precision networks to match or even exceed the corresponding high precision networks.
Some hints come from a theoretical analysis regarding how long it takes to train a network using SGD. The number of iterations required is related to the square of (a) the distance of the initial solution from the final plus (b) the maximum variance of the gradient estimates. This suggests two ways to minimize the final error. First, start closer to the solution. We therefore start with pretrained models available from the PyTorch model zoo (https://pytorch.org/docs/stable/torchvision/models.html) for quantization, rather than training from scratch as is done customarily. Second, minimize the variance of gradient noise. To do this, we combine well-known techniques to combat noise: larger batches and proper learning rate annealing with longer training time. We refer to this technique as Fine-tuning after quantization, or FAQ. Table 1 shows that the proposed method outperforms all other algorithms for quantization at 8- and 4-bits and can match or exceed the accuracy of the corresponding full-precision networks in all cases.
We found further empirical support that starting from a pretrained network was indeed helpful. The full-precision network weights were very similar to the final weights after running FAQ on ResNet-18. Given that a good 4-bit network was found close to the full-precision network suggests that it was unnecessary, and perhaps wasteful to train from scratch.
FAQ is a principled approach to quantization. Given these results on state-of-the-art deep networks, we expect that it will generate much interest, and replace existing methods. Our work here demonstrates 8-bit and 4-bit quantized networks performing at the level of their high-precision counterparts can be created with a modest investment of training time, a critical step towards harnessing the energy-efficiency of low-precision hardware.