Guest Blog by Jun Sawada, Brian Taba, Pallab Datta, and Ben Shaw.
This week, in collaboration with Lawrence Livermore National Laboratory, U.S. Air Force Research Laboratory, and U.S. Army Research Laboratory, IBM Research is publishing the newest paper describing the TrueNorth ecosystem in the International Conference for High Performance Computing, Networking, Storage and Analysis (SC16). SC16 is one of the most prestigious conferences in the HPC (high performance computing) field. Please download the paper below.
This paper describes the result of multi-year effort to create development tools and an ecosystem around the TrueNorth neurosynaptic chip. Today, we have an entire stack of hardware, firmware, software, training algorithms and applications, with active users at many university, corporate and government laboratories implementing neural computation through deep-learning and convolution networks. The diagram below, a figure from the paper, shows the entire ecosystem stack based on the TrueNorth neurosynaptic chip.
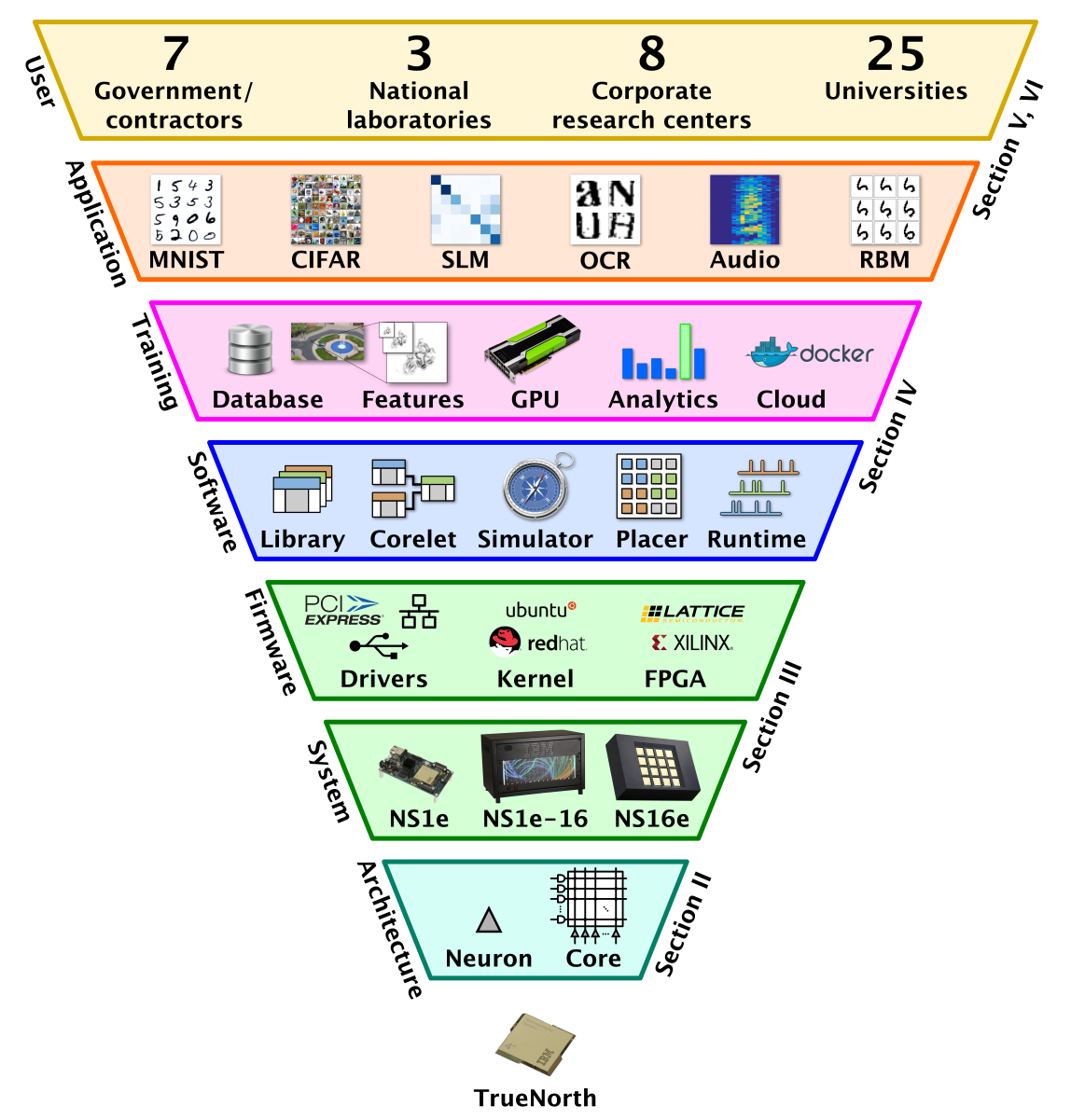
No chip will attract significant usage without a good hardware and software ecosystem. Typically when a chip maker comes out with a new processor, they can rely on existing development tools, software and chip sets, so that it is seldom necessary to build an entirely new ecosystem from scratch. However, TrueNorth was a totally new architecture for neurosynaptic computation which required building many new tools from the ground up. We have worked over the past several years to build an ecosystem, and today the toolset allows users to create deep-learning network applications for TrueNorth systems with little more than the click of a button. The paper describes these tools and the ecosystem that empowers users of the TrueNorth neurosynaptic chip.
TrueNorth Hardware
The paper describes the TrueNorth-based hardware systems we have developed: (a) a mobile evaluation board (NS1e), (b) a scale-out parallel neuromorphic server (NS1e-16), and (c) a scale-up system for running larger neural network (NS16e). The diagram below shows each system and illustrates its internal architecture.
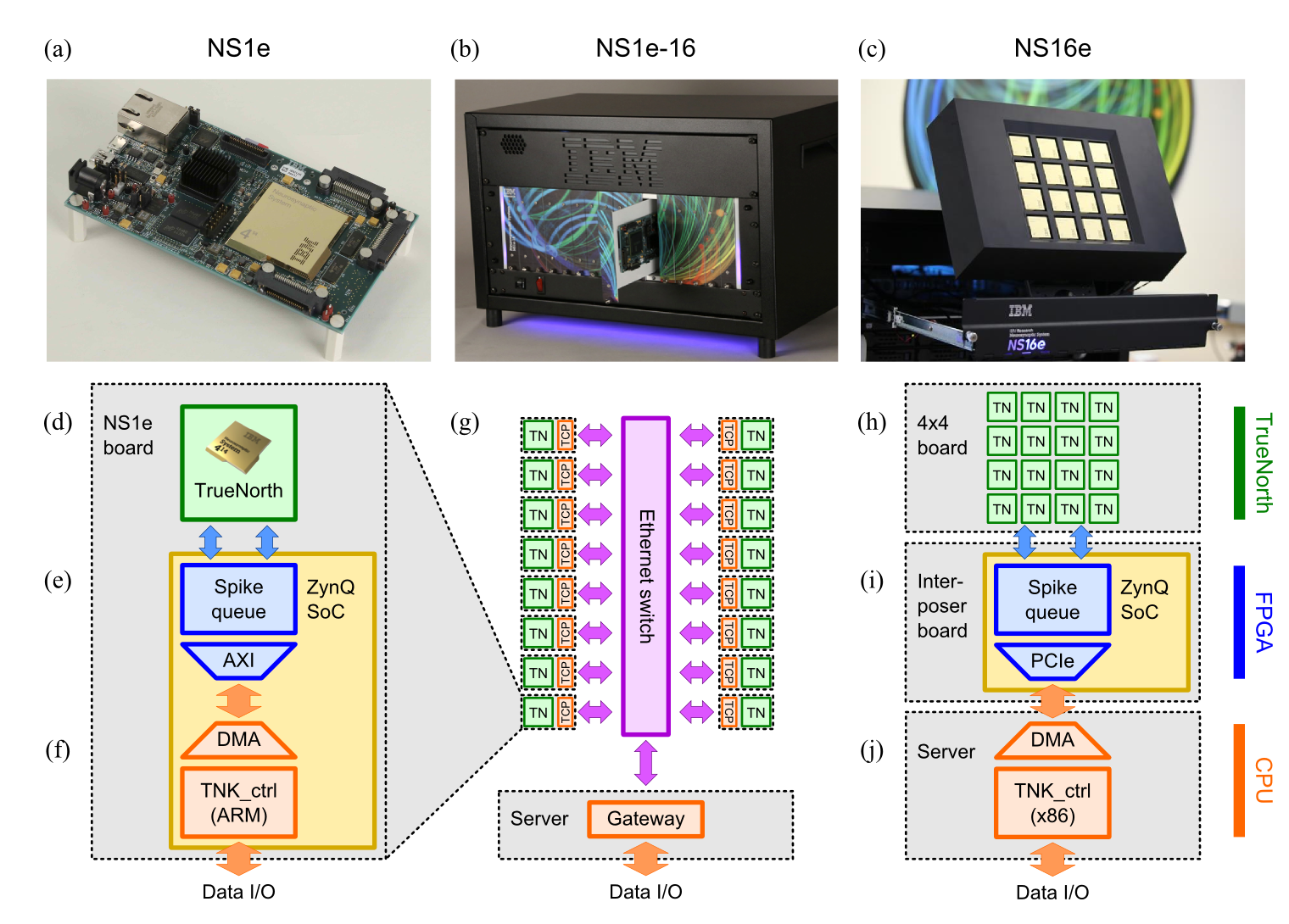
The schematics show TrueNorth chips in green, FPGA programmable logic in blue, CPU’s in orange, and network in purple. Each system runs with control software on CPU talking to TrueNorth chips with the help of programmable logic in FPGA. For details, please see the paper.
The NS1e system is an index card-sized, mobile system consisting of a single TrueNorth chip and a Xilinx Zynq-7000 system-on-a-chip. Although it is a tiny system it has proven to be our workhorse. Many of our university partners use NS1e to run and test neural networks they create for the TrueNorth architecture.

The NS1e-16 is a scale-out system running many neurosynaptic chips in parallel. It is a collection of 16 NS1e single-chip systems with an Ethernet backbone, as shown in the diagram above. When a request to execute a neural network job comes, the gateway machine picks an available NS1e automatically and dispatches the job to it. NS1e-16 is really a small neural network data-center in a box.

Finally NS16e, the scale-up system, has a tightly connected 16-chip TrueNorth array. It can run a neural network using up to 16 million neurons and 4 billion synapses. This system can run image recognition tasks (CIFAR 10, CIFAR 100) with near state-of-the-art accuracy at over 1000 frames per second.

Work Flow of Software Ecosystem
To design applications for TrueNorth, we have built a rich stack of development tools, such as our Eedn framework for developing energy-efficient deep neuromorphic networks. This generates convolutional neural networks (CNNs) that run natively in TrueNorth hardware to achieve near-state-of-art classification accuracy in real-time at very low power.
Figure below sketches a typical workflow for developing streaming Eedn applications like the gesture-recognition application we showed at the CVPR Industry Expo, or the television remote-control application we developed in collaboration with Samsung.
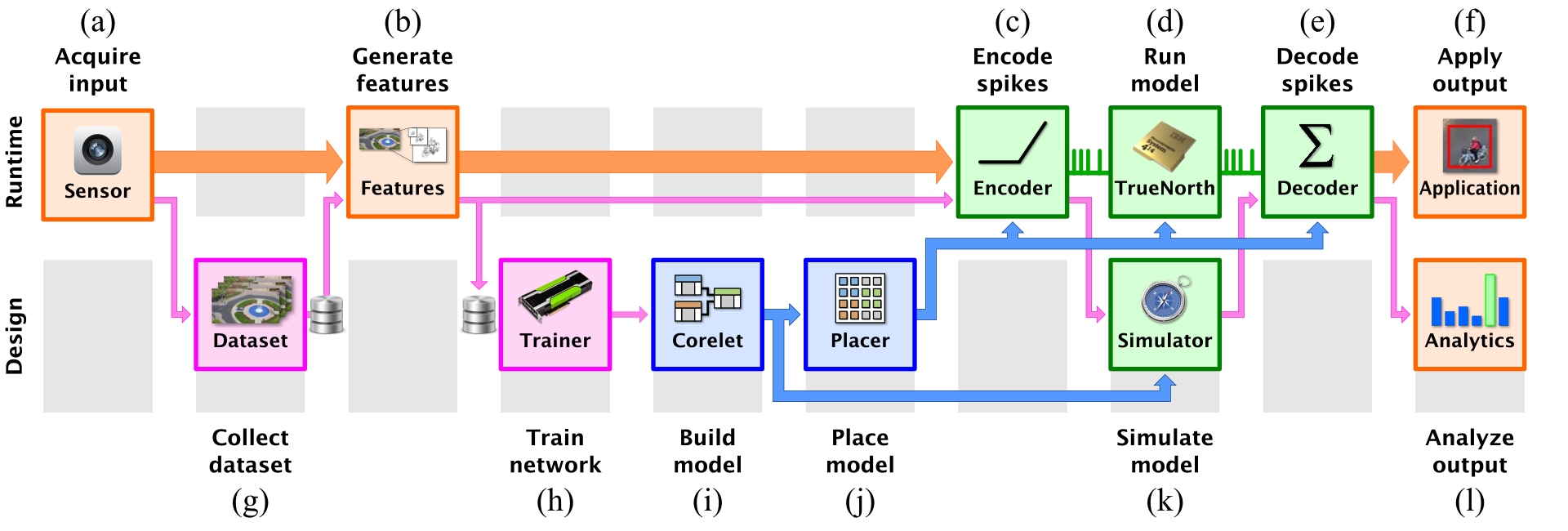
The runtime flow is shown on the top row (a)-(f). A sensor (a) produces a stream of input data. It may be a spiking sensor such as a Dynamic Vision Sensor. The original sensor data is often transformed into more specialized features (b) by cropping, filtering, or other transformation, before being encoded as a stream of input spikes (c), and sent to TrueNorth chip (d). The output of TrueNorth is decoded (e) and sent to downstream application (f).
Flow for designing an Eedn application is shown on the bottom row (g)-(l). The fundamental task is to configure the TrueNorth chip with a set of network parameters. Starting from a dataset (g), the Eedn trainer (h) uses a GPU to train a CNN within the constraints of the TrueNorth architecture. The trained neural network is built into a TrueNorth model (i) and then mapped to hardware (j). Finally, it uses simulation (k) and analysis tools (l) to improve the quality of the neural network generation.
Core Placement Problem
A TrueNorth model build at (i) is a purely logical representation of a network of neurosynaptic cores. However, to configure actual hardware, every logical core in the network must be mapped to a unique physical (X, Y) location on a TrueNorth chip by a process called placement (j)). Placement optimization is a critical issue especially for large multi-chip networks for the NS16e.
TrueNorth uses a dimension-order router, in which spikes first travel horizontally (east-west) and then vertically (north-south) between their source and destination. Figure below shows an example of routing spikes within and across TrueNorth chips.
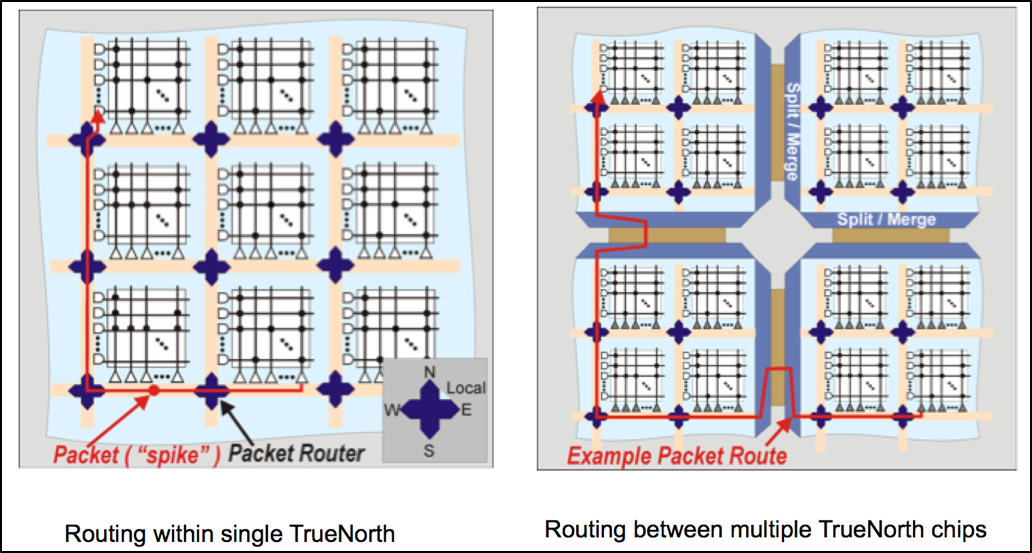
The objective of the placement is to minimize the sum of all the paths from source neurons to destination neurons, reduce the overall active power of the system, and improve the throughput. It implicitly attempts to pack all the tightly connected cores on the same chip. This problem is typically known to be NP-Hard. We developed a new NeuroSynaptic Core Placement (NSCP) Algorithm that maps the neurosynaptic cores efficiently onto the hardware substrate. The algorithm places the input neuron layer first, by collocating cores that process neighboring regions of the input signal. It then iteratively places cores in each consecutive network layer.
Lastly, a movie generated by a graph analysis tool shows how a multi-layer convolution neural network is placed on a 16-chip TrueNorth array. The visualization depicts core to core communication as edges, and illustrates how different layers of a multi-layer network are actually placed. Early layer computation is done locally while the information is shared between chips in higher layers. Some images from the movies are enclosed below.




Our Partners
As we build out the TrueNorth platform, tool chain and software ecosystem, we rely on a number of distinguished labs and other ecosystem partners to illuminate and help explore the space of TrueNorth’s application potential.
Since we held our first TrueNorth Boot Camp in August 2015 with a core group of 65 committed early adopters, our User Community has expanded to include over 150 members from 25 Universities, 7 Government labs and 3 National labs, as well as 8 corporate research centers around the world.
TrueNorth’s extremely low power profile and guaranteed real-time operation make it a natural fit for applications ranging from mobile/embedded devices to HPC and supercomputing. Table 1 from our paper lists various research areas currently under study by our ecosystem partners. The range and variety convey some idea of the space of TrueNorth application potential our partners have begun to explore.

Table of Our TrueNorth Ecosystem Partners
In May, we held a Reunion of our BootCamp community to showcase some of the amazing things that have been accomplished in just a few months. In addition to algorithmic and toolchain developments from our team, 16 posters and stage presentations were delivered by ecosystem partners. These projects illustrate a range of research topics and are a testament to the motivation and energy of our pioneering TrueNorth developers.
Three of our partners, Army Research Lab, Air Force Research Lab and Lawrence Livermore National Lab, contributed sections to the Supercomputing paper, each application showcases a different TrueNorth system.
Army Research Lab prototyped a computational offloading scheme to illustrate how TrueNorth’s low power profile might enable computation at the point of data collection. Using the single-chip NS1e board and an android tablet, ARL researchers created a demonstration system that allows visitors to their lab to hand write arithmetic expressions on the tablet, with handwriting streamed to the NS1e for character recognition and recognized characters sent back to the tablet for arithmetic calculation. Of course the point here is not to make a handwriting calculator, it is to show how TrueNorth’s low power and real time pattern recognition might be deployed at the point of data collection to reduce latency, complexity and transmission bandwidth, as well as back end data storage requirements in distributed systems.
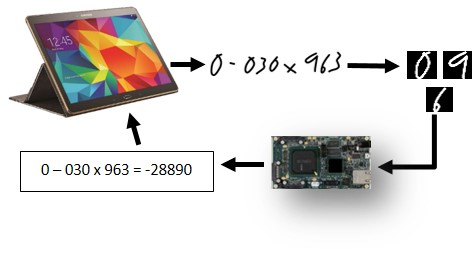
Tablet Handwriting Calculator based on TrueNorth
Air Force Research Lab contributed another prototype application utilizing a TrueNorth scale-out system to perform a data-parallel text extraction and recognition task. In this application, an image of a document is segmented into individual characters that are streamed to AFRL’s NS1e-16 TrueNorth system for parallel character recognition. Classification results are then sent to an inference-based natural language model to reconstruct words and sentences. This system is able to process 16,000 characters per second–about six times more characters than are in this section so far. AFRL plans to eventually implement the word and sentence inference algorithms on TrueNorth as well.
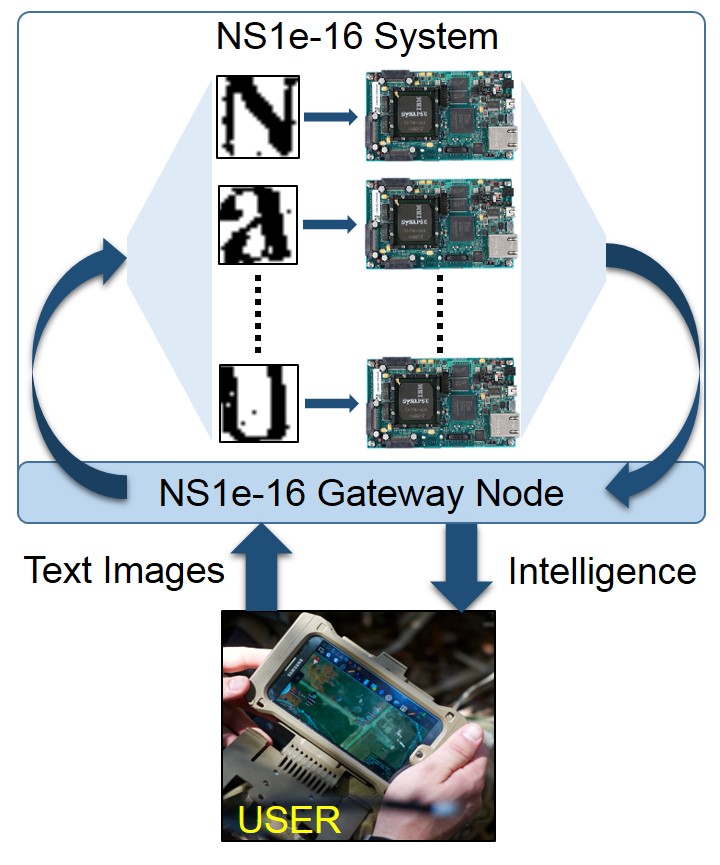
Parallel hand-written documents recognition.
Lawrence Livermore National Lab has taken delivery of a sixteen-chip scale up system to explore the potential of post-von Neumann computation through larger neural models and more complex algorithms enabled by the native tiling characteristics of the TrueNorth chip. For the Supercomputing paper, they contributed a single-chip application performing in-situ process monitoring in an additive manufacturing process. LLNL trained a TrueNorth network to recognize 7 classes related to track weld quality in welds produced by a selective laser melting machine. Real-time weld quality determination allows for closed loop process improvement and immediate rejection of defective parts. This is one of several applications LLNL is developing to showcase TrueNorth as a scalable platform for low-power, real time inference.

Manufacturing defects detected by TrueNorth classifier
It is a great honor for our team to collaborate with the many and varied members of our partner ecosystem. We are inspired by their energy, ingenuity and passion, as we set out to explore the potential of TrueNorth together!
