Guest Blog by Deepika Bablani
Title: Low Precision Policy Distillation with Application to Low-Power, Real-time Sensation-Cognition-Action Loop with Neuromorphic Computing
Authors: Jeffrey L. McKinstry, Davis R. Barch, Deepika Bablani, Michael V. Debole, Steven K. Esser, Jeffrey A. Kusnitz, John V. Arthur, Dharmendra S. Modha
Abstract: Low precision networks in the reinforcement learning (RL) setting are relatively unexplored because of the limitations of binary activations for function approximation. Here, in the discrete action ATARI domain, we demonstrate, for the first time, that low precision policy distillation from a high precision network provides a principled, practical way to train an RL agent. As an application, on 10 different ATARI games, we demonstrate real-time end-to-end game playing on low- power neuromorphic hardware by converting a sequence of game frames into discrete actions.
Link: https://arxiv.org/pdf/1809.09260.pdf
Interest in developing algorithms for energy efficient training and deployment of deep neural networks is on the rise. However, the domain of sequential decision making using RL has been relatively unexplored in this context. This is an interesting avenue for energy efficient deployment as it provides a means for deploying end to end learning agents in real world problems acting in real-time. We demonstrate, for the first time, an RL agent trained using policy distillation[1] to play ATARI games mapped to TrueNorth neuromorphic hardware. Our approach is agnostic to choice of RL algorithms and can be applied to any value based RL algorithm.
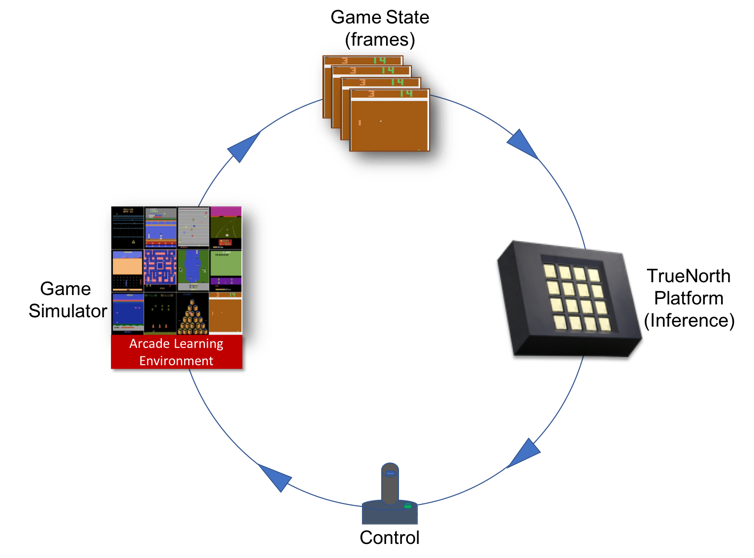
Why RL is challenging for low precision
RL solves a sequential decision making task where an agent interacts with its environment over discrete time steps, and chooses actions to maximize expected long term return [2]. Here we consider the ATARI domain. At every time step, the agent receives from the game simulator a game screen image as input. Using this, along with preceding frames, the optimal action is chosen from a discrete set to receive a reward.
Deep regression networks have been used to successfully approximate Q (state-action value) functions in value based RL[3]. These networks take raw game frames as input and predict the Q value of each action in the input state, which is used to choose the optimal policy by balancing exploration and exploitation. This is challenging for low precision networks. Q values are continuous, making value based RL a challenging regression task. To obtain the same accuracy as a network with neurons and rectified linear unit (ReLU) activations, a network with binary activations requires on the order of neurons[7], Furthermore, solving an RL problem in this constrained space is inherently hard owing to non-stationary data distribution, limited feedback and delayed rewards [3], and the amount of time required by back-propagation can be prohibitively high.
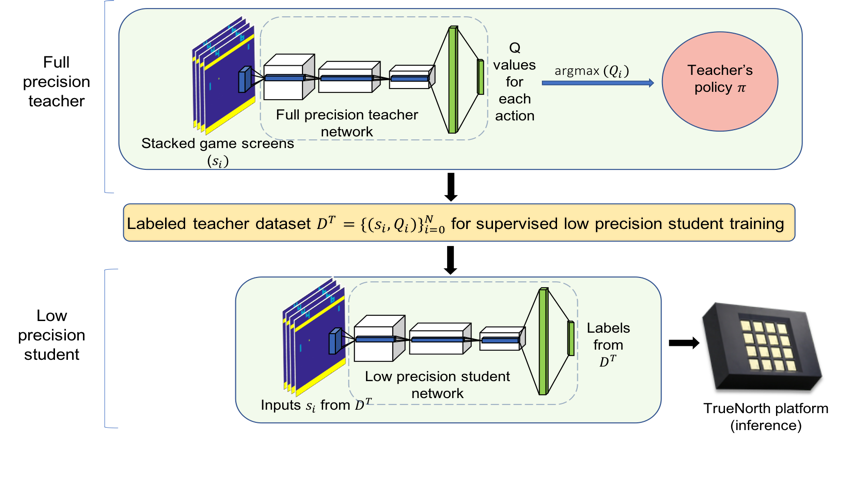
Our Approach – Low Precision Policy Distillation
Policy distillation[1] focuses on transferring knowledge from a learned policy (teacher) to a new network (student) as a supervised learning problem. The student is trained to mimic the teacher by learning to match the teacher’s actions. As the student has access to teacher’s labels, this helps overcome some challenges associated with RL. By adjusting the temperature in the distillation loss, the labels are made sharper, bringing it closer to supervised classification which is easier for a constrained student.
We used Double Deep Q Networks (DDQN)[8] to train the full precision teacher and policy distillation on data generated by the teacher to train the student. If the teacher accurately approximates the Q function, then an accurate policy can be derived from it, providing the labels to train the student network. By using policy, the final network is likely to be smaller and faster to train.
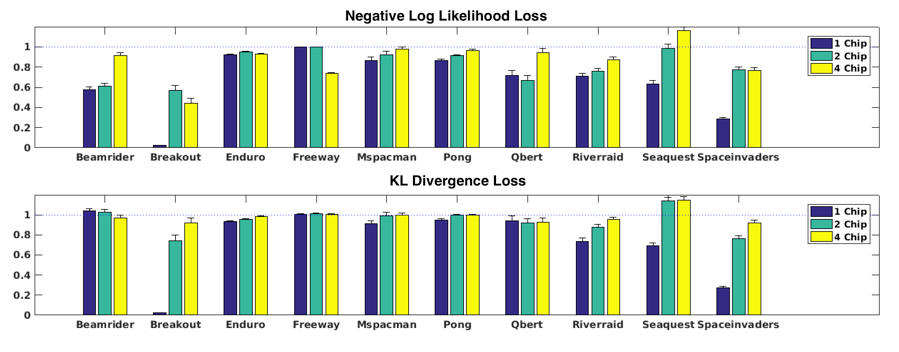
Results on the ATARI benchmark
We demonstrate results on single and multi-task policy distillation. For the single task setting, we use separately trained full precision teacher for each game. The student architecture is similar but wider and deeper. More details about TrueNorth training can be found in [9]. We use two different loss functions – Negative Log Likelihood Loss and KL Divergence Loss and compare single task results. KL Divergence loss gets better scores.
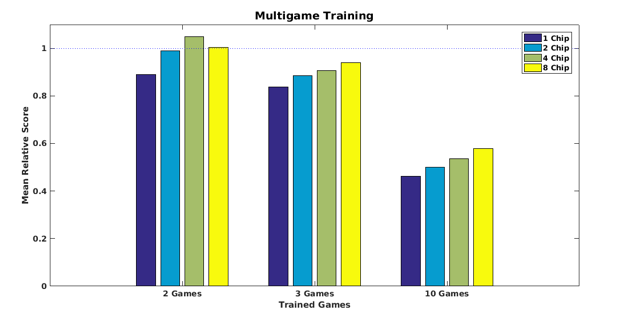
After training, student networks are mapped to TrueNorth using “corelets” [9][10]. The Neurosynaptic System 1 million neuron evaluation platform (NS1e) is a development platform which contains a TrueNorth chip alongside a Xilinx Zynq Z-7020 FPGA. Through tiling, the TrueNorth chips can be directly connected to one another via its native chip-to-chip asynchronous communication interfaces. With this, we have created a platform which natively tiles 16 TrueNorth chips, the NS16e (Neurosynaptic System 16 million neuron evaluation platform), capable of executing networks 16 times larger than those on NS1e.
The Arcade Learning Environment (ALE) was augmented for use by providing hooks into the TrueNorth run-time. We ported the entire ALE game-engine (Stella) and corresponding software modifications so they run on the ARMs while using TrueNorth for inference. The system is able to maintain a frame-rate of 30 frames-per-second(fps).
This is the first work of its kind to provide an end-to-end solution closing the sensation-cognition-action loop for real time deployment of reinforcement learning algorithms on neuromorphic hardware. This provides a strong baseline to compare future work targeted at closing the gap between algorithmic advances and real world deployment using highly optimized hardware, which is an important challenge in the current research landscape.
All figures in the blog are from the paper.
References
[1] Rusu, A. A.; Colmenarejo, S. G.; Gulcehre, C.; Desjardins, G.; Kirkpatrick, J.; Pascanu, R.; Mnih, V.; Kavukcuoglu, K.; and Had- sell, R. 2015. Policy distillation. arXiv preprint arXiv:1511.06295.
[2] Sutton, R. S.; Barto, A. G.; et al. 1998. Reinforcement learning: An introduction. MIT press.
[3] Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; and Riedmiller, M. 2013. Playing Atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.
[4]Courbariaux, M.; Bengio, Y.; and David, J.-P. 2015. Binarycon- nect: Training deep neural networks with binary weights during propagations. In Advances in neural information processing systems, 3123–3131.
[5] Rastegari, M.; Ordonez, V.; Redmon, J.; and Farhadi, A. 2016. Xnor-net: Imagenet classification using binary convolutional neural networks. In European Conference on Computer Vision, 525– 542. Springer.
[6] Esser, S. K.; Appuswamy, R.; Merolla, P.; Arthur, J. V.; and Modha, D. S. 2015. Backpropagation for energy-efficient neuromorphic computing. In Advances in Neural Information Processing Systems, 1117–1125
[7] Blum, E. K., and Li, L. K. 1991. Approximation theory and feed- forward networks. Neural networks 4(4):511–515.
[8] Van Hasselt, H.; Guez, A.; and Silver, D. 2016. Deep reinforcement learning with double q-learning. In AAAI, volume 2, 5. Phoenix, AZ.
[9] Esser, S. K.; Merolla, P. A.; Arthur, J. V.; Cassidy, A. S.; Ap- puswamy, R.; Andreopoulos, A.; Berg, D. J.; McKinstry, J. L.; Melano, T.; Barch, D. R.; di Nolfo, C.; Datta, P.; Amir, A.; Taba, B.; Flickner, M. D.; and Modha, D. S. 2016. Convolutional networks for fast, energy-efficient neuromorphic computing. Proceedings of the National Academy of Sciences 113(41):11441–11446.
[10] Amir, A.; Datta, P.; Risk, W. P.; Cassidy, A. S.; Kusnitz, J. A.; Esser, S. K.; Andreopoulos, A.; Wong, T. M.; Flickner, M.; Alvarez-Icaza, R.; et al. 2013. Cognitive computing programming paradigm: a corelet language for composing networks of neurosy naptic cores. In Neural Networks (IJCNN), The 2013 International Joint Conference on, 1–10. IEEE.