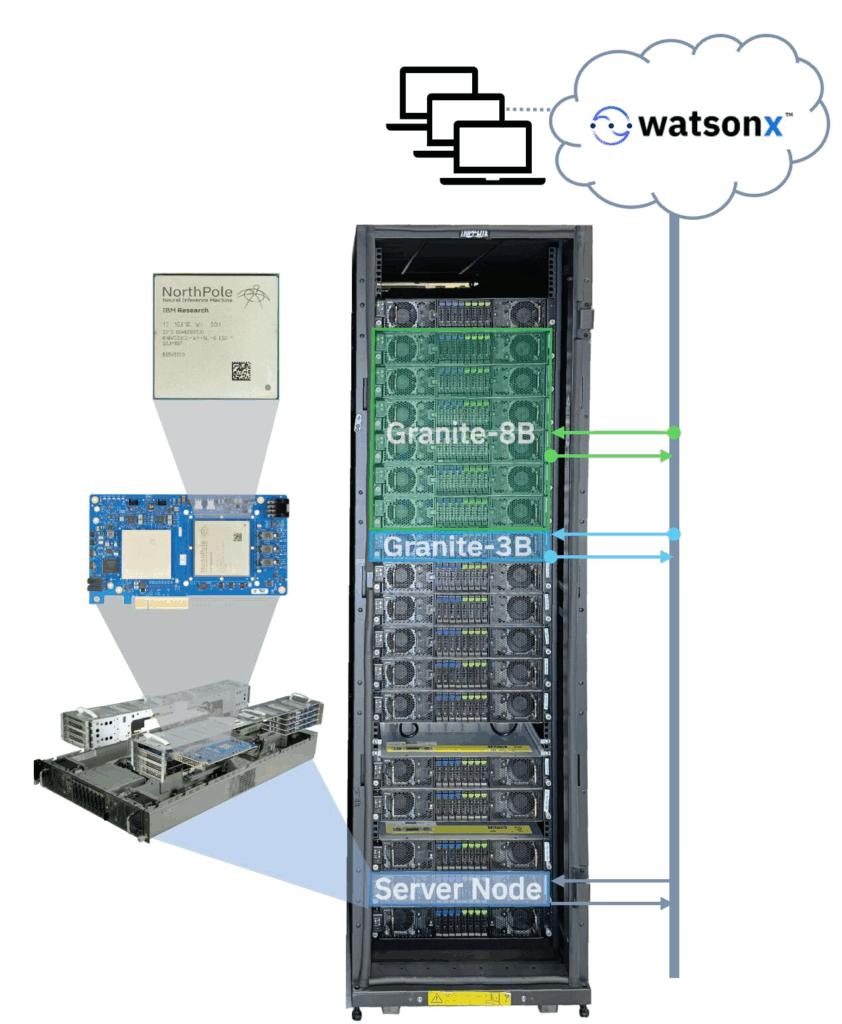
Published today (Nov 20, 2025) on arXiv (https://lnkd.in/g_r9qmZg), the IBM NorthPole Chip has been vertically integrated into an end-to-end LLM inference system comprising 288 NorthPole accelerator cards, a high-performance runtime stack, and a containerized inference pipeline.
The research prototype system delivers 115 peta-ops at 4-bit precision and 3.7 PB/s of memory bandwidth across eighteen 2U servers. The system only consumes 30 kW of power, enabling it to be deployed in existing data center (cloud or on-prem), without requiring exotic communication fabrics, custom hardware integration, liquid cooling, or facility power upgrades.
The modular, scalable, and reconfigurable system can run 3 simultaneous instances of the IBM Granite-3.3-8b-instruct model at 2,048 context length with 28 simultaneous users at a per-user inter-token latency of 2.8 ms. The same system can run 18 instances of a 3-billion-parameter model at the same context length and number of users, achieving an inter-token latency of 1 ms.
This work was done in partnership with Trent Gray-Donald at IBM watsonx and David Cox at IBM Research.
Co-authors: Michael DeBole, Rathinakumar Appuswamy, Neil McGlohon, Brian Taba, Steve Esser, Filipp Akopyan, John Arthur, Arnon Amir, Alexander Andreopoulos, Peter Carlson, Andrew Cassidy, Pallab Datta, Myron Flickner, Rajamohan Gandhasri, Guillaume Garreau, Megumi Ito, Jennifer Klamo, Jeff Kusnitz, Nathaniel McClatchey, Jeffrey McKinstry, Tapan Kumar Nayak, Carlos Tadeo Ortega Otero, Hartmut Penner, William Risk, Jun Sawada, Jay Sivagnaname, Daniel Smith, Rafael Cardoso Fernandes Sousa, Ignacio Terrizzano, Takanori Ueda, Trent Gray-Donald, David Cox, Dharmendra Modha
NorthPole is a brain-inspired, silicon-optimized chip architecture suitable for neural inference that was published in October 2023 in Science Magazine. Result of nearly two decades of work by scientists at IBM Research and a 15+ year partnership with United States Department of War (Defense Advanced Research Projects Agency (DARPA), Office of the Under Secretary of War for Research and Engineering, and Air Force Research Laboratory). For more information, see:
– Science paper: https://lnkd.in/g2bZ3Gfv
– IBM Research Blog 1: https://lnkd.in/gn6vP8xZ
– IBM Research Blog 2: https://lnkd.in/gHhH9hKb
– Dharmendra Modha’s Blog: https://modha.org
– Computer History Museum: https://lnkd.in/gFUemm6F
– Hot Chips Symposium video: https://lnkd.in/gCQMdz_Y
– LinkedIn Post: https://lnkd.in/g2bZ3Gfv
– LinkedIn Post: https://lnkd.in/gbMqcP5S
– LinkedIn Post: https://lnkd.in/g9tVcJZT
– LinkedIn Post: https://lnkd.in/gj5yWD77
– LinkedIn Post: https://lnkd.in/gkXpavmh
– Linkedin Post: https://lnkd.in/gpf_ktk3