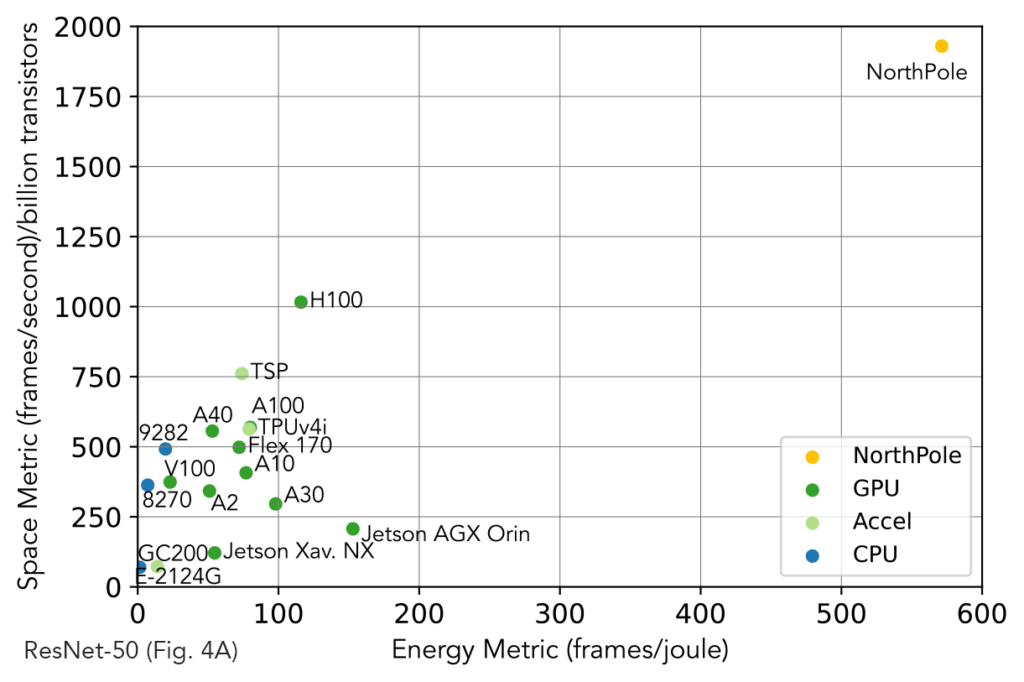
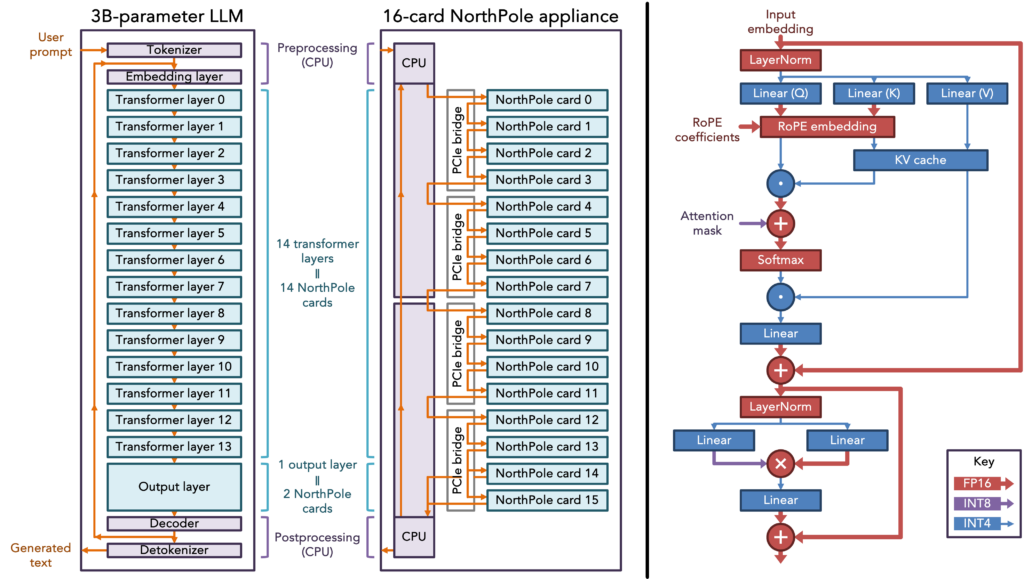
New: As presented at the IEEE HPEC Conference (High Performance Extereme Computing) today, exciting new results from IBM Research demonstrate that for a 3-billion parameter LLM, a compact 2U research prototype system using the IBM AIU NorthPole inference chip delivers an astounding 28,356 tokens/sec of system throughput and sub-1ms/token (per-user) latency. NorthPole is optimized for the two conflicting objectives of energy-efficiency and low latency. In the regime of low-latency, NorthPole (in 12nm) provides 72.7x better energy efficiency (tokens/second/W) versus a state-of-the-art 4nm GPU. In the regime of high-energy efficiency, NorthPole (in 12nm) provides 46.9x better latency (ms/token) versus a 5nm GPU.
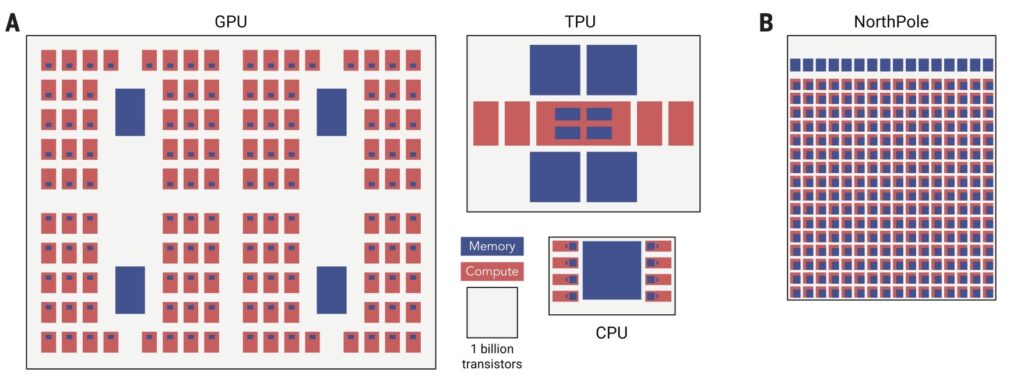
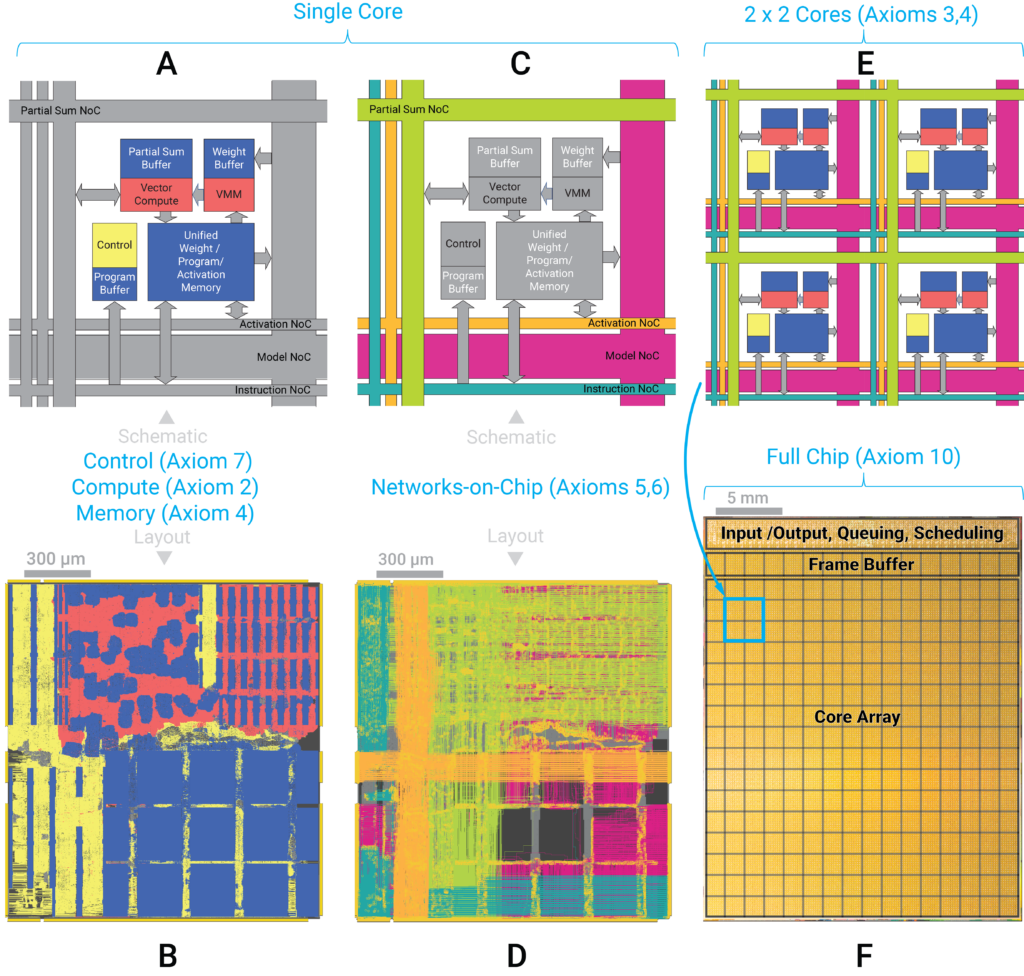
NorthPole is a brain-inspired, silicon-optimized chip architecture suitable for neural inference that was published in October 2023 in Science Magazine. Result of nearly two decades of work at IBM Research and a 14+ year partnership with United States Department of Defense (Defense Advanced Research Projects Agency, Office of the Under Secretary of Defense for Research and Engineering, and Air Force Research Laboratory).
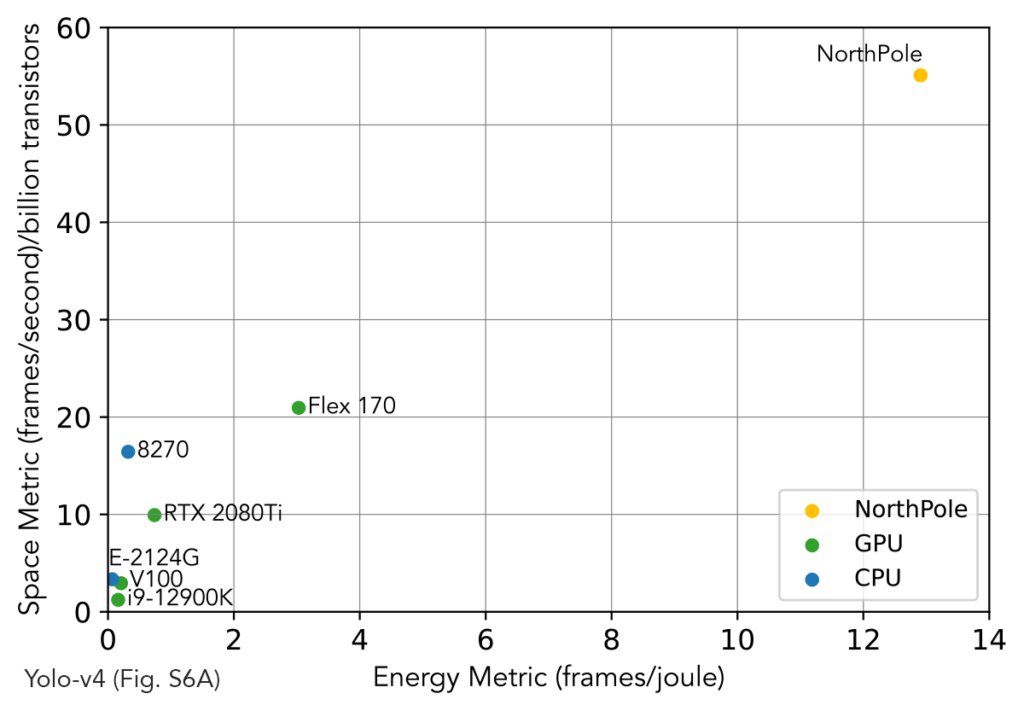
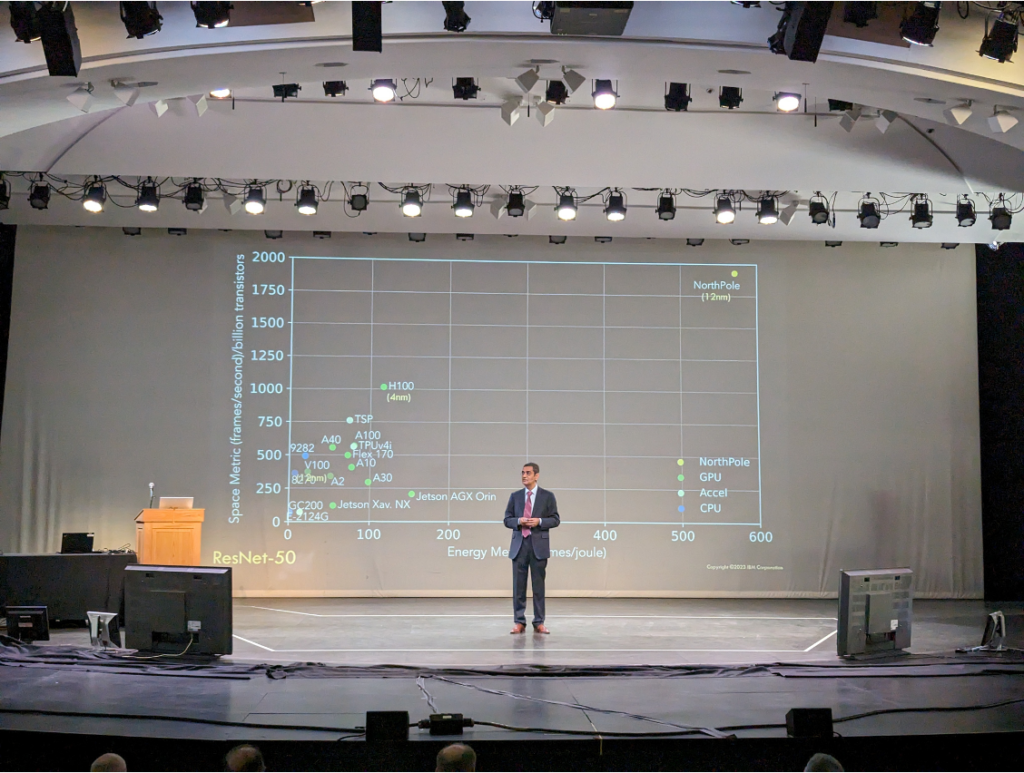
NorthPole balances two conflicting objectives of energy efficiency and low latency.
First, because LLMs demand substantial energy resources for both training and inference, a sustainable future computational infrastructure is needed to enable their efficient and widespread deployment. Energy efficiency of data centers is becoming critical as their carbon footprints expand, and as they become increasingly energy-constrained. According to the World Economic Forum, “At present, the environmental footprint is split, with training responsible for about 20% and inference taking up the lion’s share at 80%. As AI models gain traction across diverse sectors, the need for inference and its environmental footprint will escalate.”
Second, many applications such as interactive dialog and agentic workflows require very low latencies. Decreasing latency, within a given computer architecture, can be achieved by decreasing throughput, however, that leads to decreasing energy efficiency. To paraphrase a classic systems maxim, “Throughput problems can be cured with money. Latency problems are harder because the speed of light is fixed.”


PDF of the Accepted Version.
Future: Next research and development steps are further optimizations of energy-efficiency; mapping larger LLMs (8B, 13B, 20B, 34B, 70B) on correspondingly larger NorthPole appliances; new LLM models co-optimized with NorthPole architecture; and future system and chip architectures.

Design Credit: Ryan Mellody, Susana Rodriguez de Tembleque, William Risk, Map Project Office